

A More Practical Approach to Encrypting Data in Motion
Justin Smith, Pivotal’s Chief Security Officer for Product, breaks down encrypting data in motion into a more approachable understanding.

It’s now a foregone conclusion that data traveling over a network should and must be protected. “Thou shalt encrypt data in motion” is a universal commandment. In addition to agreeing with common sense, it’s required to comply with industry standards such as PCI.
There are a few ways to protect data in motion, but all of them create an encrypted channel for moving data. This encrypted channel can exist at the application layer or at the transport layer. We often select transport layer protections given our desire for code reuse and the wealth of battle-hardened encryption technologies at the transport layer. Therefore, this post focuses exclusively on the transport layer, but the concepts apply elsewhere.
I’m often asked which of the two most widely used mechanisms for transport layer encryption is better: Transport Layer Security (TLS) or IPSec. Historically this has been an architecture debate, but I’m seeing it more and more in terms of security posture. I tend not to answer these types of questions in binary terms, so my answer is “it depends”. This post describes how I think about the problem, and it may prove helpful in your own decision making. All of the information contained here is available elsewhere, but it’s usually described in a way that positions it as unapproachable pedagogy. My goal is to provide security teams with a more useful and approachable understanding of the issues to better equip technical organizations to make informed and reasoned decisions on encrypting data in motion.
Protecting data in motion means encryption. Before we begin, let’s cover some cryptography to ensure a common baseline.
Cryptography 101
First, let’s consider the operative use case: process A communicates with process B over a network. Our perennial concern is the malicious participant, process C. We’re concerned process C might understand or manipulate the interaction. Process A will encrypt the information it sends to process B over the network. If it’s done correctly, it’s infeasible for process C to understand what’s communicated. In addition to providing confidentiality, it’s also advisable for process A and process B to reliably identify themselves to each other. It’s bad news if process C can decipher their communications, but it’s arguably worse if process C can successfully pose as either process A or process B. In simplest terms, we want to authenticate the messaging participants while also ensuring message confidentiality and integrity.
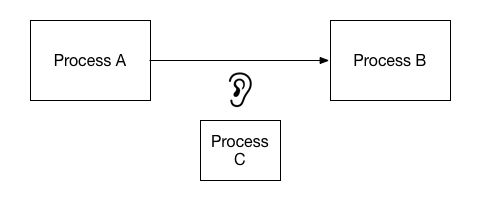
Authentication: Prove that I am who I claim to be
Confidentiality: Ensure that data can only be read by intended and authenticated recipients
Integrity: Ensure that data is not tampered with or falsified
The question is ‘how?.’ Today this means public/private key cryptography. The often-misunderstood terms batted around in this realm include X.509 certificates, Certificate Authorities, RSA, Elliptic Curve Cryptography, one-way hashes, and digital signatures. Luckily none are conceptually hard to understand. The public and private keys are numbers with a special relationship. Disclosure and use of the public key does not reveal the value of the private key and vice-versa. The message sender and receivers have different keys, so we often refer to these keys as asymmetric. A message sender can encrypt data with one key and the receiver needs the other key to decrypt it.
RSA and Elliptic Curve Cryptography are two classes of algorithms that achieve these characteristics. The keys associated with these algorithms can be serialized and encoded in special files called X.509 certificates. Certificates contain a ton of other information like names, network addresses, and dates. When people refer to certificates, they usually are referring to X.509 certificates that contain public keys.
Data (like certificates) can be digitally signed. Digital signatures are encrypted hashes. A good hash function is one that’s hard to reverse and not prone to collisions. If you apply a good hash function to a message, the result of the function does not reveal anything about the original message. Further, a good hash function applied to any two messages are not likely to have the same resultant value (also called a collision). Examples of common hash functions include MD5, SHA1, and SHA2. MD5 and SHA1 are prone to collisions. SHA2 is much less prone to collisions than SHA1. To add a digital signature to a file, you create a hash of the file, encrypt it with a private key, then store the encrypted value somewhere. The verifier performs the same hashing function, obtains the public key and uses that public key to decrypt the ciphertext. The verifier compares the cleartext to the calculated hash function. If they match, the verifier knows the data hasn’t been altered since signing. The verifier also knows that the signer had possession of the private key associated with the public key.
Why sign a certificate? When one applies this type of digital signature to a certificate, it provides assurances about the ownership and validity of the data in the certificate. In reality it’s just pushing trust further upstream. The entities that perform these types of operations on certificates are called Certificate Authorities (CA). Public Key Infrastructure (PKI) is the machinery around the certificate lifecycle.
One of the problems with public/private key cryptography is a limitation on the amount of data one can encrypt in a particular session. Let’s say you need to encrypt a 100kb message. Suffice it to say that It’s pretty hard to do that with today’s public/private key cryptography. We need something faster and better able to handle more data. That leaves us with symmetric encryption. Symmetric encryption, as implied by the name, requires both participants to have possession of the same key. If process A and process B want to encrypt their communications, they both need possession of the same key. This creates a huge problem. How do process A and B get the same key?
Keys expire and keys leak.
The naive answer is for one participant to generate a symmetric key, encrypt it using asymmetric cryptography, and send the encrypted key to the other participant. Imagine process C records all network traffic between process A and process B over a long period of time. Keys expire and keys leak. At some point process A’s private key could become available to process C. At that point, process C can decrypt all past communications between process A and B. It’s also possible the communications are still valuable to process C. It may sound far-fetched, but this is a very real scenario in a surveillance state.
Let’s consider how we avoid sending the symmetric key over the network. As it turns out, there’s a class of functions that allow both process A and process B to individually derive the same symmetric key. The concept is pretty simple. Process A and Process B need to perform some local mathematical computations, and exchange their intermediate results. The functions they perform are a specialized form of key derivation functions. The parties need to exchange their intermediate results to ensure that the final result of the computation comes out the same for both parties. When they are done, they share a common secret key. Joy. Best of all, even an eavesdropper who has watched the entire exchange occur is not able to learn the final shared key, because it was never sent over the network. The most common class of key exchange is called Diffie Hellman. There’s a form of Diffie Hellman for RSA and for Elliptic Curve Cryptography.

Perfect Forward Secrecy
Now consider the case of leaked private keys. In other words, process A and process B use their secret private key and the public key encoded in a signed certificate. If these keys leak, then process C can once again decrypt previous communications between process A and B. There’s no guarantee that the communications that are secret today are secret in the future. We want secrecy that’s valid today while also being forward looking. We call this characteristic Perfect Forward Secrecy (PFS).
There’s no guarantee that the communications that are secret today are secret in the future. We want secrecy that’s valid today while also being forward looking.
We obtain PFS with ephemeral keys, that as the name implies, are very short lived. Process A wants to talk to process B. Process A initiates the handshake with process B. Process A will, during the handshake, verify the identity of process B by checking its certificate (name, signed by the right CA, etc.). Process B can optionally require process A to identify itself by requesting it to present a certificate. Both processes will generate an ephemeral public/private key pair. They will then exchange ephemeral public keys over the network. Remember this key exchange — it will be hugely important later.
After both participants have exchanged ephemeral public keys, they will use a key derivation function to calculate the same symmetric key. That symmetric key will be used to encrypt future communications. It’s valid for the session. The session key is not written to disk or sent over the network. It’s not related to the relatively static public key encoded in their signed certificate. Therefore, it achieves perfect forward secrecy since compromise of long term static key does not compromise past session keys. All this is required for process A and process B to identify each other and establish a symmetric key that’s perfectly forward secret.
Conceptually, that’s all there is to establishing a unique session key that’s perfectly forward secret. Every session gets a new session key that’s unrelated to the public and private key pair used for authenticating the messaging participants.

So, which one is better?
Notice that I didn’t talk about any specific security protocol like TLS, mutual TLS, or IPSec. That’s intentional. TLS, mutual TLS, and IPSec are different ways to arrive at a symmetric key that’s perfectly forward secret. Put another way, TLS, mutual TLS, and IPSec can use the same key agreement primitive. They simply exist at different levels of the software stack.
TLS, mutual TLS, and IPSec are different ways to arrive at a symmetric key that’s perfectly forward secret
TLS and mutual TLS are application-level constructs. IPSec is an operating system construct. TLS gives the client the opportunity to authenticate the server, but does not provide the server the opportunity to authenticate the client. Mutual TLS allows the server to authenticate the client and vice-versa. IPSec is usually mutually authenticated. The session keys in TLS and mutual TLS are known only at the application layer and not intended to be shared amongst multiple processes. The session keys in IPSec are available to the IPSec daemon and surfaced as a network device, so any process on the server with permissions to see the network device can use the session keys. The encryption that happens at the IPSec layer is completely transparent to applications.
In the case of TLS, mutual TLS, and IPSec, there’s no clear “better” protocol. They can resolve to the same encryption circuit, but they operate at very different levels of the stack.
Design Considerations
Selecting the right protocol requires some understanding of their strengths and constraints. I find it often helpful to consider the threats the protocol is intended to mitigate. Within the threat and protocol arena, I tend to consider the following questions:
- What’s the performance?
- What’s theoretically going to have access to session keys?
- What’s going to come in contact with the private key?
Performance
Channel encryption performance varies wildly with settings. As we’ve seen previously, PFS session keys require an additional network exchange. If your channel is setup for PFS, you will definitely see this impact if you’re generating lots of new sessions. Your only two options are: (a) switch to a cipher suite that doesn’t provide perfect forward secrecy or (b) reuse existing sessions.
As an example, consider this very real scenario. Let’s say regulations require you to terminate TLS inside an application container. Let’s say the usage of your application *without* TLS requires 100 application instances. Let’s also say that you have a load balancer in front of those 100 application instances that randomly directs traffic to one of the 100 application instances. This means there’s a strong likelihood that subsequent requests from a single client will route to a different application container. Turning on TLS with PFS session keys in this scenario will destroy performance. It means that nearly every client request could trigger session key negotiation. Another alternative is to pin a client to an application container, which can create problems at the routing layer.
Performance will dramatically increase if you terminate TLS at the load balancer and use IPSec to secure the network segment between the load balancer and the application container. There tend to be fewer load balancers, so client requests are likely to end up at the same device and pinning is easier. This reduces the velocity of session creation. The 100 sessions between the load balancer and the application containers are reused amongst client requests.
Session Key Access
If an attacker can gain access to a session key, they can decipher network traffic for that session. From the prior example, using IPSec between the load balancer and the application container means that it’s possible to man-in-the-middle the interaction. Maybe there’s a rogue process on the load balancer or on the server hosting the application container. Such a process could decipher *all* client traffic. This is not possible if you terminate inside the application container. This is truly a case of performance clashing with security posture.
Access to the Private Key
Terminating TLS in the application container implies the application has direct access to the private key used for endpoint authentication. This type of credential tends to have a long lifetime, often in years. Application developers tend to dump parts of memory to logs for debugging purposes. In addition, log files tend to have more liberal access control policies than the environments that produce them. This can create a nightmare scenario, all it takes is one debug line to a log file and the private key could leak. Credentials are more likely to leak if they are exposed to an application. This sounds like it’s simple to avoid, but in practice it’s quite hard to enforce this level of behavior across large numbers of engineers. I’m calling it out explicitly because it happens often. This simple fact can have an impact on where to terminate TLS.
There are several other aspects to consider, like diversity of endpoint ownership, complexity of credential rotation, and cost of making code changes. In my experience, performance and key exposure are the most influential.
Conclusion
Data in motion should and must be encrypted. The current wave of cloud platforms have highlighted this requirement in a big way. We tend to rely on transport mechanisms for confidentiality and integrity, which leads us to three options: TLS, mutual TLS, and IPSec. We’ve seen how the need for perfect forward secrecy forces us to consider performance and key access. There’s no 1-size fits all solution, but hopefully there’s enough information here to help you make a more informed decision about what’s right for your organization.

Change is the only constant, so individuals, institutions, and businesses must be Built to Adapt. At Pivotal, we believe change should be expected, embraced and incorporated continuously through development and innovation, because good software is never finished.

A More Practical Approach to Encrypting Data In Motion was originally published in Built to Adapt on Medium, where people are continuing the conversation by highlighting and responding to this story.



















