

 This week at the ACM SIGMOD Conference, the premier international forum for database researchers, practitioners and users, Pivotal announced the architectural benefits and results for its brand-new cost-based query optimizer. The results bore out Pivotal’s statement that HAWQ is the world’s fastest SQL query engine on Hadoop®, with benchmarks demonstrating it is capable of up to 21 times faster performance and three times the queries supported for Hadoop®. Moreover, it showed the performance and productivity improvements that an ANSI SQL compliant optimizer such as HAWQ can offer in comparison to other solutions which only offer SQL-Like Compliance.
This week at the ACM SIGMOD Conference, the premier international forum for database researchers, practitioners and users, Pivotal announced the architectural benefits and results for its brand-new cost-based query optimizer. The results bore out Pivotal’s statement that HAWQ is the world’s fastest SQL query engine on Hadoop®, with benchmarks demonstrating it is capable of up to 21 times faster performance and three times the queries supported for Hadoop®. Moreover, it showed the performance and productivity improvements that an ANSI SQL compliant optimizer such as HAWQ can offer in comparison to other solutions which only offer SQL-Like Compliance.
The paper, titled “Orca: A Modular Query Optimizer Architecture for Big Data,” includes benchmark results based on the TPC-DS, a well-known decision support benchmark that models several generally applicable aspects of a decision support system.
This blog post will deep dive on Section 7 of the paper to focus on the highlights of performance and scalability against other SQL and SQL-like query engines for Hadoop®. (For more highlights on the paper, please refer to the previous blog on this topic).
TPC-DS Test and Results
[Disclaimer: Although the SQL queries used in these performance tests are based on those specified in TPC-DS benchmark specification, these performance test results have not be audited by a TPC-certified auditor, and therefore, are not being claimed as the official TPC results.]
The test consisted of 25 tables, 429 columns, and 111 queries. Each environment was made up of 10 nodes—2 for HDFS name node and coordinator services of SQL engines and 8 for HDFS data nodes and worker nodes. Each node had a dual Intel Xeon eight-core processors at 2.7GHZ, 64GB of RAM and 22 900GB disks in JBOD. The operating system used was Red Hat Enterprise Linux 6.2. We tested the following: CHD 4.4 and Impala 1.1.1, Presto 0.52, Hive 0.12 for Stringer, and PHD 1.1 and HAWQ 1.1. (Although this test was conducted earlier this year and new releases and advancements may have occurred since then, this test used generally available/production versions. We will continue to follow up with the results of newer releases of HAWQ and other systems).
The results on average lead HAWQ having 6x faster performance against Impala and 21x faster performance against Stinger.
The charts above can be found in the paper and show the speed-up ratio for the queries we could run for Impala and Stinger against HAWQ. (*) denotes instances in which Impala ran out of memory on certain queries.
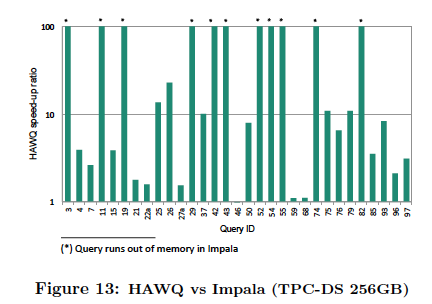
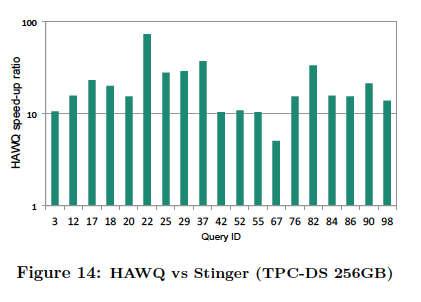
HAWQ is able to achieve faster performance results for two reasons: the fundamental difference in the query optimizers’ architectural maturity, and its SQL standard compliance versus SQL-like compliance.
Rule-based and Cost-based Query Optimizers
A pure rule-based optimizer blindly applies a predefined set of rules to produce an executable query plan. For example, always use a particular join/aggregation algorithm if some condition holds (e.g. the query has simple equality conditions). This is obviously very limited because it does not take into account the size of data that the algorithm is going to process when executed, nor the size of output the algorithm is going to generate. This often leads to arbitrarily bad execution plans often found in immature query engines for Apache Hadoop®.
A cost-based optimizer is more intelligent. It has a cost model that estimates the time of each possible execution strategy and picks the one with the least estimated time. It uses a lot of statistical measures to do this estimation, including data distributions, number of distinct values, frequent values. These statistical measures are often collected offline, and the optimizer uses them during query optimization.
Pivotal HAWQ, a feature of Apache Hadoop® distribution Pivotal HD, and Greenplum’s highly mature query optimizer, code named Orca, are cost-based. This means that the optimizer has a set of fixed rules that allow it to generate different execution plans. However, the application of these rules is guided by cost estimates. The optimizer may avoid applying a rule, if it knows that it will lead to a bad plan. The output of applied rules is costed based on the cost model, and the best plan is picked according to that resulting in faster query performance.
SQL Standard Compliance vs. SQL-Like Compliance
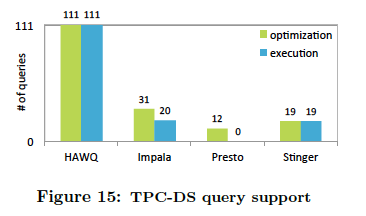
It’s very critical to note that HAWQ was able to run all TPC-DS 111 queries. Impala could only run 31 queries, Stringer 19 queries, while Presto could run only 12 queries. This meant we were only able to test performance on the queries that all solutions could run. Impala, Stringer, and Presto are unable to run all the standard TPC-DS queries (without re-writing) that any Enterprise Data Warehouse (EDW) or Analytical Data Warehouse (ADW) can execute. This is because they are not ANSI SQL compliant. In addition, there were many circumstances where they simply ran out of memory. Full SQL compliance is required if you want to run industry standard analytic tools and BI user interfaces without having the need to continually tweak/rewrite the query
So what about the other 80 queries in the industry standard TPC-DS benchmark? There are many features missing from SQL-like query engines compared to ANSI SQL compliant HAWQ, such as ORDER BY without LIMIT, Intersect, stddev_samp (analytics standard deviation), roll up (quick for totals and subtotals), coalesce (oracle compatibility), null expression, etc. In the interest of brevity, we will focus in this post on the following four frequently used features and their impact to the analytics lifecycle:
1. Correlated Subqueries
This is a critical SQL standard construct in data warehousing that allows users to effectively express complex relationships between different data sets in a compact way. The alternative to correlated subqueries is using multiple nested inner/outer/semi joins, which is not easily expressible for large queries. Orca does the conversion from correlated subqueries to joins automatically, while it is missing in all the other SQL-like query engines that were tested. This is required for executing ~ 20% of the TPC-DS benchmark. Here’s an example of such a query:
Query 10: Count the customers with the same gender, marital status, education status, purchase estimate, credit rating, dependent count, employed depended count and college dependent count who live in certain counties and who have purchased from both stores and another sales channel during a three month time period of a given year.
While it is possible to rewrite the query to avoid correlated subqueries, however it is very difficult and often time consuming to rewrite and maintain these queries. Rewriting the query requires applying non-straightforward concepts from relational algebra, introduces the risk of error, and often many BI tools provide these queries outside of the box (auto-generated). Therefore rewriting the query will cause compatibility issues with many leading BI tools as well.
Because HAWQ is ANSI SQL compliant, it delivers the capabilities of correlated subqueries, analyst and data science efficiencies, and stronger integration with BI tools from Oracle, SAS, IBM Cognos, and MicroStrategy.
2. Window functions
This is a sophisticated SQL standard feature and is essential in many commonly used analytic workloads. Many financial services and manufacturing organizations use window functions for rolling averages, cumulative distribution, data ranking, event processing, etc. Window functions perform a calculation across a set of table rows that are somehow related to the current row. The use of this feature allows data scientists and analysts to explore and analyze large data sets using a compact, yet powerful construct. Window functions are fully supported by HAWQ, and unsupported by Impala. (For more details, please refer to our previous blog on window functions and time series analysis).
Query 67: Find top 100 stores for each category based on store sales in a specific year is an example for Window functions.
There may be possible workarounds to replace window functions with multiple nested joins, which requires complex skillsets of relational algebra. In addition to the error-prone aspect of this approach, the rewrite end result may lead to a query plan with unacceptable performance as data grows for production environments–queries tend to run long and in our instance even run out of memory.
The reason is that executing window functions requires extensive grouping, aggregation and join operations. HAWQ includes one highly optimized operator that efficiently performs these tasks collectively. This operator usually delivers superior performance compared to an equivalent join-based rewrite. None of the other SQL-on-Hadoop systems have a similar functionality.
Rewriting the query removes the automation that is already built in place leading to slower performance, higher probability of discrepancy that can lead to the wrong answer, and even worse if implemented negatively impact business decisions, operations, and even revenue.
As questions get more complex, queries get more complex. Automation capabilities become more critical while exploring different hypotheses (what-if analysis). With window functions, HAWQ simplifies and delivers efficiency and optimized execution to ad-hoc queries.
3. Large number of joins including multiple fact/dimension tables
This is a pattern that commonly occurs in star schemas, which are widely adopted by many organizations.
Query 25: Get all items that were sold in store in a particular month and year and returned in the next three quarters, and repurchased by the customer through the catalog channel in the six following months. For these items, compute the sum of net profit of store sales, net loss of store loss, and net profit of catalog. Group this information by item and store. (Query 25 contains 2 big fact tables, sales and catalog with an 8-way join).
Query 54: Final all customers who purchased items of a given category and class on the web or through catalog in a given month and year that was followed by an in-store purchase at a store near their residence in the three consecutive months. Calculate a histogram of the revenue by these customers in $50 segments showing the number of customers in each of these revenue generated segments.
Both queries ran out of memory with Impala. The main underlying problem is the size of intermediate join results. With multiple large fact tables, intermediate join results may not fit in memory, and need to be spilled to disk. If the query execution framework does not have the ability to spill to disk, the execution usually terminates with an out of memory error. There are workarounds, such as adding predicates to eliminate data that does not contribute to query results. It can prove difficult to guess from the query text, resulting in high chances of wrong results. And it’s clear throwing more memory at the problem is not an efficient means of scalability, as noted in a recent Twitter post. The size of memory needed is disproportionate to the data size itself and in our attempt didn’t even factor in concurrent users, which would require more memory.
HAWQ can support up to 34 joins, by far the most for a SQL query engine on Hadoop® for complex joins that data scientists often run. Moreover, HAWQ has highly efficient memory utilization.
4. Dynamic Partition Elimination
Data partitioning is a well-known technique for achieving efficiency and scalability when processing large amounts of data. Some of the well known-benefits of data partitioning include reduced scan time by scanning only the relevant parts, and improved maintenance capabilities: data can be loaded, indexed, or formatted independently.
Pivotal has taken a big step forward by eliminating partitions from a query plan that contains data not relevant to answering a given query. In other words ,we are able to limit the amount of data you need to scan automatically. By eliminating the amount of data that needs to be scanned we can achieve better performance results. To learn more how we are able to achieve this, please refer to the white paper “Optimizing Queries over Partitioned Tables in MPP Systems”.
As described earlier, partition elimination in Query 25 is data dependent. This means that you need to know values contained in the dimension table in order to decide which partitions can be eliminated from fact table, making it almost impossible to perform workarounds. If you were to rewrite the query, you would need to do so each time the data set changes. The longer time for analysis could result in increased time to market.
Again with this advanced feature, HAWQ produces plans that eliminates partitions on the fly during query execution, which is another reason of why HAWQ achieves highly efficient query execution.
In Closing
SQL continues to be one of the most widely used languages in the database community. At this month’s Hadoop® Summit, many new SQL-like vendors have come to market. As more production workloads migrate from the Enterprise Data Warehouse (EDW) to Hadoop®, retaining a similar SQL standard compliance experience will be essential to maintain performance, reliability of results, and productivity.
TPC-DS is a decision support benchmark that models the query workloads in many real-world data warehouses. If a data management system is unable to optimize/execute the benchmark, without rewriting/changing the queries, this prompts serious questions whether the solution is the right choice for Big Data analytics in Apache Hadoop® environments.
Choosing a system with mature architecture and intelligent cost-based optimizer ensures efficient query execution impacting service-level agreements (SLAs) of downstream applications. Full SQL compliance leverages existing skillsets and removes the need to rewrite and continually monitor and maintain many queries that are usually automatically generated removing the risk of human error and lengthened data scientist and analyst time.
By supporting a rich set of SQL standard constructs and building on powerful optimization and execution frameworks, HAWQ demonstrated that it is the SQL-on-Hadoop engine that many organizations need to expand their data capabilities while retaining the speed and performance they require.
To learn more about the tests, please refer to the full paper, “Orca: A Modular Query Optimizer Architecture for Big Data.”
Learn more about Pivotal HD with HAWQ
Learn more about the Pivotal Big Data Suite
Editor’s Note: Apache, Apache Hadoop, Hadoop, and the yellow elephant logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
About the Author





















